A PATTERN IN PHISH'S PREDICTABILITY
Of the many elements of the Phish.net feature set, one that often catches my curiosity is Trey's Notebook. It identifies songs most likely to be played at each show, given songs played in the previous year but not the previous three shows.
For upcoming shows, it's an algorithmic prediction ("Here's what you might expect to hear...") that often works remarkably well, such as predicting 68% of the 22 songs played three nights ago in Rochester. But for previous shows, focus on those percentages themselves rather than the list of songs, and Trey's Notebook becomes a measure of the extent to which Phish's setlists are predictable.
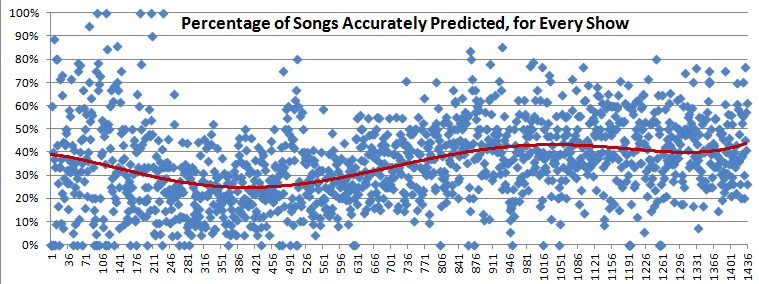
That varies widely, as this first chart illustrates. A handful of early shows were completely predicted (100%!), but many were predictive #fails (0%). Shows in 1990-93 were generally less predictable than shows before or since, largely as a function of the repertoire expanding during that period. And there's a general pattern, marked here with a fifth-order polynomial trendline, in maroon, though nothing stark. (Note that this scatterplot replaces an earlier, clunkier lineplot.)
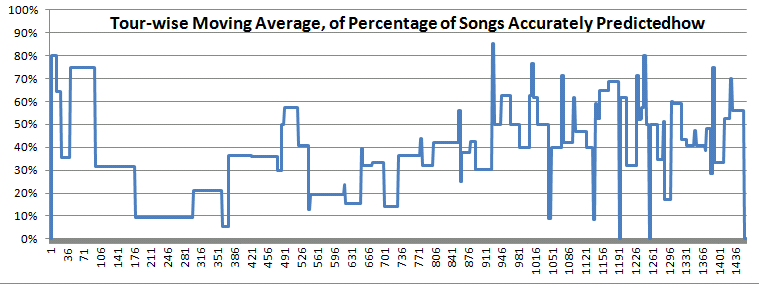
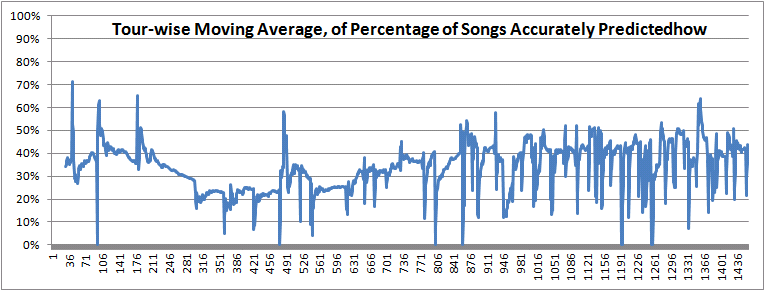
Since the predictability also varies by tour, I also tried charting tour averages (depicted on a per-show basis, for comparison of both predictability and tour length) and tour-wise moving averages (for each tour, the first show's percentage predicted, then the first two shows' percentages averaged, then the first three, etc.) However, the lengths of tours (particularly as we define them) vary widely, with up to 121 shows in one "tour." And the percent correctly predicted varies across tours, generally increasing from start to finish, with an average percentage correct of 23.4% across the first shows of every tour but an average of 35.4% across the last shows of every tour.
So, this final chart averages, for each show, the percentage correctly predicted at the previous 30 shows. This "30-show moving average" is telling: Save for a few pronounced dips, Phish setlists have been getting generally more predictable over the past 20 years, such that Trey's Notebook now routinely predicts around 40% or more of each what the band plays. But, then, that's the case for the bulk of the past 700 shows - nearly half the band's history!
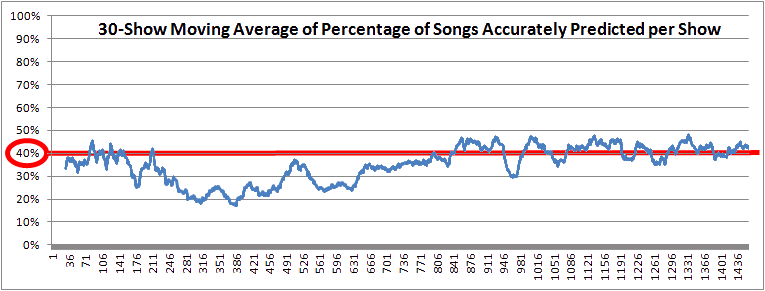
So, the next time some doe-eyed city reporter writes an article calling Phish "unpredictable", well, you can correct them: Maybe not so much as they used to be!
None of this analysis would have been possible without Adam's build of Trey's Notebook, and Stephen's backend querying to collect the data. Thanks to you both for fueling the infoporn!
Comments
You must be logged in to post a comment.
 The Mockingbird Foundation
The Mockingbird Foundation{kind=link}
{kind=link}
{kind=link}
Although the predictability seems to be increasing, it's not rising appreciably. Note in the first figure that the scatter of the data is actually decreasing... there are less wildly predictable and totally unpredictable shows. I'd submit that Phish 3.0 are more mature musicians, so perhaps they're finding a better formula that works for them. Maybe they're trying to let certain songs evolve to a greater degree before rotating them out?
It'd be interesting to compare these trends with a proxy for how 'enjoyable' the shows are. Does predictability correlate with awesomeness?
Also those numbers are inflated from the number of songs in Trey's Notebook. Sure, it can predict 65% of songs played, but they list 36! The bigger that number, the more 'impressive' that percentage gets.
And @NoHayBanda is right, to an extent, both that the actual variability in songs affects the input to Trey's Notebook, and that the precision of the predictions (how many songs are listed) affects the output. But actual variability should impair the predictions, which might actually do a better job if that were considered; and higher or lower precision would alter the percentages but might not appreciably changes *in* those percentages, which is what I was after.
Hey, if anyone wants to provide a better input to improve the algorithm that fuels our predictions, I'm all ears. Email me.
More detail in the other post, but here is a link to that spreadsheet. I updated this through the 2013 Dick's run. Song totals are 98% correct or so, give or take a couple here and there. I really enjoy nerding out to Phish.
the reason shows were so 'unpredictable' early was due to heavy repeats. just look at any notebook and compare it with a gap chart for that show. i randomly looked at 02.07.1991
http://phish.net/treys-notebook?basedate=1991-02-07
due to the rules of treys notebook, this show was highly unpredictable. when in reality, there were THIRTEEN repeats from the night before. and five more on a 2 show gap.
due to their small song catalog, they were flooded with massive repeats early in their career, trey's notbook just isnt set up to evaluate them properly.
(insert "these aren't the labels you're looking for" joke here.)
My mistake, I was looking at the Notebook for 10/26! total fail on my part
There are of course other ways to mean or measure predictability. We could create a composite measure combining the Trey's Notebook "anticipated percentage" (which assesses recent commonality) with the show's "last time played" average (which assesses the appearance of rarities, relative to what's common and whatever's in the middle.) And there are probably other things that would be fun to throw in the mix.
Nice work here.
ELLIS GODARD YOU FUCKS
SELL, SELL, SELL!
(1) The elimination of songs in the last three sets is arbitrary and introduces a sharp discontinuity in eligibility. Instead I would suggest penalties for being played recently, with the penalty decreasing by show separation. To illustrate what I mean, the penalties could be -15 for one show back, -10 for two shows back, -5 for three shows back, -2 for four shows back, and -1 for five shows back.
So if David Bowie has been played 17 times in the past year, but it was played one show ago, DB would get assigned a score of 2. If YEM has been played 13 times in the past year, but it was played three shows ago, it would get a score of 8.
Then whichever songs get the highest scores would be the predicted ones. In essence, this is exactly the scheme being used, except the penalties right now are -1000 for any songs in the past three shows, and 0 for all other songs.
Naturally, there is nothing magical about the penalties I chose above. There would probably have to be some tinkering done. Assuming it's not too tough, you could mess around with the penalties and observe the resulting average prediction accuracy. Then pick whatever penalties maximize average prediction accuracy over the shows so far.
(2) I wonder if the one year cutoff is optimal in terms of establishing the score for each song. Perhaps you could tinker with this. Again if it's not too hard, you could try different cutoff points and see which one maximizes average prediction accuracy.
In the unlikely event that my advice is implemented, I would suggest doing my second suggestion first. The cutoff point is going to make a big difference in terms of which penalties are optimal.
as a different kind of prediction, there could be a new section called something like "they are due for a..." where you can take songs with larger gaps, and compare the current gap to them (ie. the sloth has a 3.0 gap average of 18.9, and is currently at 26. this could get a rating of 1.37, or however you scale it.
it would mostly be made up of songs that don't make the trey's notebook cut, but its always fun to think about what rarities could be due up soon
If it's been played on the current tour, the penalty could be based on the average gap on the tour. If its its been played in the past 12 months but not the current tour, the penalty could be based could be the average gap in the last 12 months, with possibly a penalty or bonus for not appearing yet in the current tour. If it hasn't been played in the last 12 months, the gap could be based on the average historical gap, with possibly an additional penalty or bonus for not having been played in more than a year.
And if we're adjusting the "last seen" penalty, the one-year/12-month cutoff is of course also arbitrary. Maybe it should be the last 30 shows, or the last 3 tours, or the number of shows we'd expect to see within the next year as projected from a moving average of the number of shows seen in past years, or...
It seems critical to note that since the band is writing less new songs, this would affect predictability in a big way. Though i dont know that this would 'prove' anything. If we agree they should be writing/adding material, then the lack of this aspect is simply a problem in itself, perhaps associated with--but not directly affecting--calculations of predictability.
just a thought, and certainly not original with me, i expect.
First set will open with KDF, Chalkdust type of jam, etc. (it always peaks and ends too soon) Then comes Moma Dance or Back on the Train (not really ever outside the box. You get a Rift, Bluegrass tune, Gin, and they close it out with a rocker. There is always a tasty little diversion in there (see, MPP2 It's Ice, Scent or even MPP 2011 Wolfman's Boogie on).
Second set is the bread and butter for fans of improv - most if not all highlights of 3.0 come from this opening sequence of the second set. Certainly, I've seen some great stuff the past few years in this slot, most recently the Hampton night 2 Ghost-DWD-Steam. Then the set cools down with Caspian or Wading before a Hood or YEM takes us home.
Encore is Loving Cup or another classic rock cover.
I must stress, this is not to say that I don't LIKE this structure because I do and I respect the way they have honed the show into one that fans from all eras and styles of the band will leave feeling happy. I haven't left a 3.0 show unhappy out of the 7 I have seen. It's just different from the 97-99 Phish I absolutely loved. You never knew what set, date, city, or venue the would burn down.
Thanks for the Phish geekdom. I enjoy this talk.
Dosque